はじめに
2006年~2007年にかけてノロウイルスの爆発的な流行が発生し、マスコミを賑わせたことは記憶に新しい。この流行の大部分は、ノロウイルスの遺伝子型の一つであるGII/4によるものであった(10)。この現象は日本に限らず、アメリカ(2)やヨーロッパ(11)、オーストラリア(1)など世界中で起きている。何故、ノロウイルスの特定の遺伝子型が流行しているのか、ウイルスの病原性や伝播のしやすさとノロウイルスの遺伝子型に関係があるかなど、ノロウイルスのゲノム塩基配列を基に精力的に研究が進められている。また、最近の疫学調査の結果、従来主因となってきた二枚貝の生食によるノロウイルスの食中毒は減少し、ヒトからヒトへのいわゆるヒト—ヒト感染が大きな割合を占めることも明らかになってきた。厚生労働省では、ノロウイルスによる食中毒および感染症の発生が大幅に増加したことに鑑み、2007(平成19)年8月17日および9月21日、薬事・食品衛生審議会食品衛生分科会食中毒部会を開催し、今シーズンに向けての“ノロウイルス食中毒対策(提言)”を取りまとめた(http://www.mhlw.go.jp/shingi/2007/10/s1012-5.html、http://www.mhlw.go.jp/shingi/2007/10/dl/s1012-5a.pdf)。この中に“食中毒判断根拠の明確化”という項目があり、ノロウイルスの遺伝子型調査を判断根拠の一つに挙げている。ノロウイルスの遺伝子型は、疫学調査上の重要なデータとして注目されているばかりでなく、食中毒の判断基準としても利用されている。
本稿では、ノロウイルスの遺伝子型について、基礎から最新の知見までを概説する。
ノロウイルスのゲノム構造と遺伝子型分類法
ノロウイルスは、約7,500塩基のプラス一本鎖RNAをゲノムに持つウイルスである。ノロウイルスのゲノムには3つの蛋白質コード領域(open reading frame; ORF)が存在しており、ORF1;非構造蛋白質、ORF2;構造蛋白質1(VP1)、ORF3 ;構造蛋白質2(VP2) をコードしている(9)。ノロウイルスのゲノム塩基配列は多様性に富んでおり、ゲノム塩基配列の相同性に基づきいくつかのグループ、遺伝子型(ゲノタイプ)に分類されている。これまでに、非構造蛋白質のRNA依存性RNA合成酵素(RNA dependent RNA polymerase, RdRpもしくはpolymerase)をコードする領域を用いた遺伝子型分類(ゲノタイピング)や、VP1領域を用いたゲノタイピングが報告されている。特に我々の構築したVP1領域を用いたゲノタイピング(7)は、ノロウイルス粒子の抗原性をよく反映する(3)ため、ゲノタイピングの主流となってきた。我々はこの方法によってノロウイルスの抗原性を予測し、組換えバキュロウイルスを利用したノロウイルスのウイルス様中空粒子(VLPs)を作出し、ノロウイルスの抗原性について研究を重ねてきた。この研究成果は、体外診断薬として認可されたELISA法や、イムノクロマト法によるノロウイルス診断キット開発に役立てられた。VP1領域を用いたゲノタイピングは、ノロウイルスの迅速診断を推進してきたのである。
最近、流行の主流を担っているノロウイルスは、VP1領域のタイピングによってGII/4に分類されるウイルスである。オランダの研究グループは、このGII/4を細分化するためRdRp領域を用いたタイピングを行い、流行株を区別している。彼らは、RdRpの遺伝子配列の違いがノロウイルスの複製効率に関与し流行株出現の一因となる可能性を示唆し、RdRpによるタイピングを推進しようとしている(12)。
ノロウイルスはRdRp領域とVP1領域の間でゲノムの組換え(リコンビネーション)を起こすことが知られている(5)。この領域はORF1,2 junctionと呼ばれており、リコンビネーションのホットスポットとして認知されている(4, 9)。ノロウイルスのゲノムリコンビネーションは、ノロウイルスの宿主への適合やウイルス病原性の変化等を理解する上で重要な現象なのだが、ノロウイルスのゲノタイピングを混沌とした状態に陥れている元凶の一つでもある。つまり、ORF1,2 junction上流のRdRp領域を用いたゲノタイピングと、下流のVP1領域を用いたゲノタイピングで異なる結果を与えるリコンビナント株が存在するためである。厳密に言えば、ノロウイルスの場合、分子時計が算出できていないので、リコンビナントが元株なのか、元株がリコンビナントなのか断定できない。つまり、どちらが祖先で、どちらが子孫か分からないのである。
ノロウイルスは、現在までにVP1領域のゲノタイピングを用いて、36種類以上のタイプが報告されている(7, 13, 14)。やっかいなことに、ノロウイルスは予想以上に多数のリコンビナント株が存在することに加え、新しいタイプを報告した研究者が、独自に命名したゲノタイプ番号を新しいゲノタイプに付けるため、混沌とした状況に陥っている。そこで、ここでひとまずタイピングの基本に戻り、改めてノロウイルスのゲノタイピングについて考え直してみたい。
分類学上のノロウイルスの位置
少し遠回りだが、ノロウイルスのゲノタイピングを知る上で、ウイルスの分類学上ノロウイルスは何処に位置するのかを確認してみよう。ウイルスの分類は、形態学的特徴、病原性、ゲノムの構造などを加味して、国際ウイルス命名委員会(International Committee on Taxonomy of Viruses; ICTV、http://www.ICTVonline.org/index.asp)が決定する。ICTVのウイルスデータベース; ICTVdBの、カリシウイルスの項目(http://www.ncbi.nlm.nih.gov/ICTVdb/ICTVdB/12000000.htm)に、ノロウイルスはカリシウイルス科に属するウイルス属として定義されている。カリシウイルス科(Caliciviridae )には、現在4つのウイルス属(genus)の存在が認定されている。Vesivirus , Lagovirus , Sapovirus , Norovirus である。通常ウイルス属にはいくつかのウイルス種(Species)が含まれているが、Norovirus (ノロウイルス属)には今のところNorwalk virus(ノーウォークウイルス種)以外のウイルス種は無い。我々が通常使用している“ノロウイルス”という呼び名は、実はウイルス属を示すものであり、ウイルス種を意味するものではない。仮にノロウイルス属に他のウイルス種が発見されれば、この呼び方を改める必要が出てくるのかもしれないが、今のところ“ノロウイルス”が“ノーウォークウイルス”を意味するとしておいてもよいだろう。
ノロウイルスのゲノタイピングの現状
昨(2007)年11月にメキシコのカンクーンで行われた第3回国際カリシウイルスミーティングでは、国際ウイルス命名委員会(ICTV)のカリシウイルス分科会のミーティングも同時に行われた。このミーティングで、カリシウイルスファミリーの新しいウイルス属、“Nebovirus "(仮称)が認められた。このウイルス属はイギリスとアメリカのグループが相次いで発見し、欧文紙に発表したウシのカリシウイルスであるため、正式な名称は両者間の話し合いの後決定されることとなった。この席では、オランダの研究グループから一昨年から爆発的な流行が続いているノロウイルスの遺伝子型を細分化する案が出された。しかし、ICTVの規約には“family(科)"、“genus(属)"、“species(種)"の定義があり、これに基づいてウイルスを分類している。ICTVが関与するのはここまでであり、これよりも細かい分類であるゲノグループやゲノタイプなどには関与しない。従って、この案は却下されICTVの分科会は終了した。続いて分科会とは別に、ゲノタイピングに関する話し合いが行われた。CDCを中心とするアメリカのグループ、オランダを中心とするヨーロッパのグループがゲノタイプの番号に関する主導権を争ったため、混沌とした状況に陥ってしまった。日本から、何を目的としてゲノタイピングを行っているのかを再考する必要があるとする動議を出したため、協議は番号の争いではなく、目的の確認へと変化した。結論として、現行のゲノタイピングは、ノロウイルスの抗原性を予測するための手段であることが確認された。ICTVは、培養細胞による増殖系がないウイルスの場合、完全長のゲノム塩基配列もしくは、意味を持つ程度の長さの塩基配列情報に基づいて分類を行うべきとしている。従って、特にノロウイルスのようにリコンビナント問題を抱える場合は、できる限りゲノム全長を用いてタイピングが行われるべきであることも確認された。さらに、現行のVP1領域を用いたゲノタイピングで新しいゲノタイプを名乗る場合、少なくともVP1領域全長の塩基配列情報を必要とすることが確認された。番号の統一、方法論の統一はなされなかった。この会議の記録は、Archives of Virologyの別冊としてまとめられる予定である。
以上のことから、ゲノタイプ番号を含め、ゲノタイピングは今後もなお混沌とした状態が続いていくと考えられる。そこで、代表的なタイピング方法と、それに基づくゲノタイプ番号をまとめたので以下に示す。
VP1のN末端領域のパーシャルシーケンスを用いたタイピング
この方法は、PCRのゴールデンスタンダードとなっているSK primer seriesによる増幅産物から得られる塩基配列情報を用いたゲノタイピングであり、これまでに著者らが推奨してきた方法でもある (7) 。
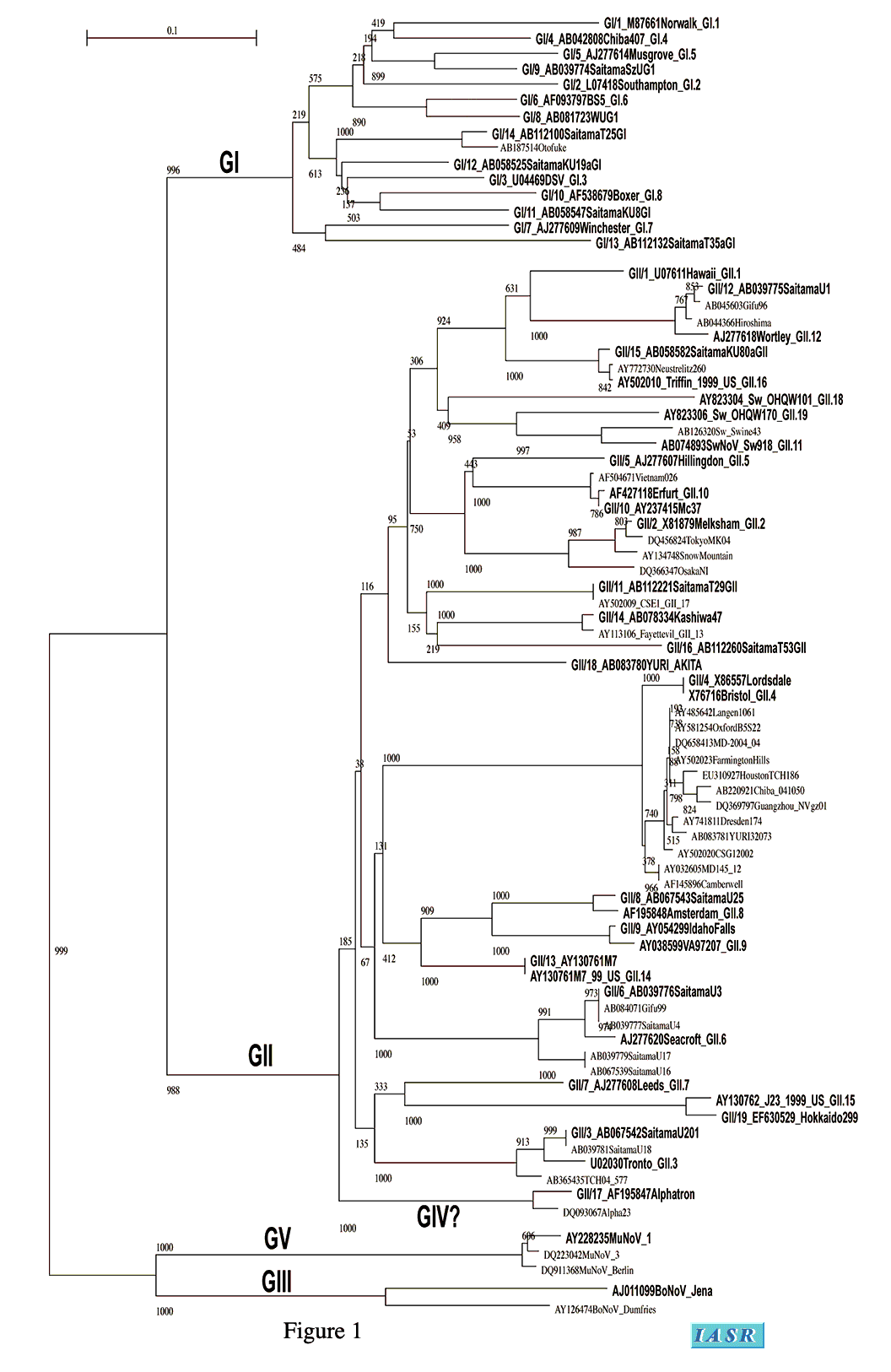
ノロウイルスの検出には、ウイルス性下痢症診断マニュアル、厚生労働省のノロウイルス食中毒対策(提言)にも記載されているリアルタイムPCR法(COG primer, RIN probe set)(6)を用いることが推奨されるが、陽性検体のゲノタイピングには再度SK primer seriesでPCRを行い、増幅産物を得る必要がある。増幅産物の塩基配列を決定すれば、ゲノタイピングに必要な塩基配列情報が得られる。得られた塩基配列をCaliciWeb (http://teine.cc.sapmed.ac.jp/~calici/modules/news/)にアップしてある基準配列ファイルに加え、同様にCaliciWebにアップしてあるプロトコールに従ってClustalWで解析を行うと、ゲノタイピングの結果が得られる。本ゲノタイピングは、我々の構築した方法に準拠したタイピングであり、ゲノタイプ番号の付け方もその延長上にある(後述するAlphatron株を除く)。この基準配列ファイルには、できる限り完全長塩基配列の報告されている株と、論文として報告され、データベースから塩基配列が取得可能な株を選択した。さらに、Fields Virology 5th editionに記載されているゲノタイプ標準株も含まれている。アクセッションナンバーの左側に我々の方法に基づいたゲノタイプ番号を、最後尾にFields Virology 5th editionに基づいたゲノタイプ番号を記載した。このファイルを用いて作製したNJ法による分子系統樹をFigure 1に示した。
この領域を用いたタイピングの限界として、ゲノグループIV(GIV)としてコンセンサスが得られつつあるAlphatron株が、ゲノグループII (GII)クラスター内部に入ることが挙げられる。CDCのグループは、キャプシド領域全長の塩基配列データを決定し、アミノ酸配列に変換後に最尤法で分子系統解析を行う方法(後述する)を推奨している。キャプシド全長約1,600塩基の塩基配列を得るためには、ゲノム3´末端にあるpoly A配列からのlong RT-PCRを用いる必要がある。また、増幅産物の塩基配列解析も一度のシーケンス反応では解読し終わらない長さである。仮に、この方法を用いた場合もGIVの遺伝学的な距離はGIIクラスターから十分に離れているとは言えず、ゲノグループとゲノタイプの境界線に位置することに変わりはない。我々は、genotypeクラスターのVLPを作製し、各々の抗原性を調べたところ、Alphatron株のVLPはGIIのVLPに対する抗体と交差反応することを明らかにした(3)。この結果から、抗原性の観点から見ると、Alphatron株はGIIクラスターに存在しても矛盾はないのである。つまり、抗原性を予測するためのゲノタイピングとして、本方法は、その目的を十分に果たすと言える。
CDCの提唱するゲノタイピング
CDCは、前述のVP1のN-terminal & S region (N/S region)領域を用いたタイピングではゲノタイピングが正確にできないとして、VP1領域全長の塩基配列をアミノ酸配列に変換して、最尤法でタイピングする方法を構築して報告した(14)。この方法に準拠してゲノタイピングを行う場合、VP1領域全長のアミノ酸配列情報、つまりVP1領域全長の塩基配列情報が必要になる。Fields Virology 5th editionは、CDCとの事前打ち合わせに基づいて編集されており、CDCの方法に記載された塩基配列を標準株として用いている。表1に、Fields Virology 5th editionに記載された標準株と、我々が用いている標準株の対応を示した。しかし、Fields Virology 5th editionの標準株には、依然として論文上に報告が無い株も含まれているので、塩基配列の信頼性には注意が必要である。また、同じゲノタイプ番号が分子系統樹(Figure 1)における同じゲノタイプクラスターを示すとは限らないので、ゲノタイプ番号の対応は分子系統樹上で確認する必要がある。
本法とN/S領域を用いた方法との違いは、Alphatron株のクラスターの位置、解析に要求する塩基配列・アミノ酸配列の長さである。まず、Alphatron株のクラスターの位置について説明する。本方法では、Alphatron株のクラスターがGIIクラスターの外から分岐するため、GIVとしてAlphatron株のクラスターを認識しやすくなる。しかし、分子遺伝学的な計算に基づくAlphatron株と他のゲノグループの株との距離は、N/S領域を用いた場合と大差はなく、ゲノグループ間との距離と、ゲノタイプ間との距離の中間値を取っており、統計学的に有意に分別することはできない。ここには研究者の主観が入り込む恐れがある。いずれにせよ、抗原性の違いを予測する目的でタイピングを行うのであれば、どちらの方法で行っても大差はない。次に、本法ではVP1全長の塩基配列が必要である。たかだか1,600塩基ではあるが、この領域をPCRで増幅するためのプライマーをデザインするのは難しい。なぜなら、VP1の下流にはすべての株間で相同性の高い塩基配列を有する領域は、ゲノム末端のポリA配列とその近傍にしか無いためである。特に新しいタイプを解析する場合、PCRで増幅産物が得られる保証はない。また、増幅産物の塩基配列も、解読を必要とする塩基長が長いため、一度のシーケンス反応では決定できない。目的がN/S領域のタイピングと同じなら、無理に本法を用いる理由はない。しかし、数塩基のミスマッチを利用してノロウイルスの感染経路を特定するのが目的である場合、本法は有用性が高い。VP1は、ノロウイルスゲノムの中で最もホモロジーの低い領域であるP2ドメインをVP1領域の中程に含むため、株間のわずかな違いを見つけることができるからである。
ポリメラーゼ領域を用いるタイピング
主にオランダのグループが中心になって行っているタイピングである。彼らは、最近流行しているGII/4のポリメラーゼ領域の塩基配列を解析し、2006a, 2006bなど幾つかの型に細分化した(12)。これらの型の違いはアミノ酸配列にして数残基である。彼らは、ポリメラーゼにはゲノムの複製を行う活性があることから、これらのアミノ酸変異が、ノロウイルスの複製効率と関係している可能性を挙げ、この領域を用いた分類を推奨している。この領域を用いたタイピングは、ノロウイルスの抗原性を予測するVP1領域のタイピングとは異なる、新たなノロウイルスの性質を分別できるかもしれない。しかし、感染モデル動物や、培養細胞を用いたヒトに感染するノロウイルスの増殖系が無い現在、ノロウイルスの増殖効率や病原性などを実証することはできず、ポリメラーゼ領域を用いたノロウイルスの分別にどのような意味があるかは不明である。また、分子遺伝学的観点から見た場合、ポリメラーゼ領域を用いた解析は、ゲノグループを分別することは可能だが、ゲノタイプを分別することが難しい。それは、遺伝学的距離が幾つから幾つまでがゲノタイプという定義付けができないからである。遺伝学的距離に基づいたタイピングを行う際には、遺伝学的距離(genetic distance or distance)を横軸に、縦軸に度数(どの程度の頻度でdistanceの値が出現したか)をとってグラフを描いた場合、アイソレートもしくはストレイン、ゲノタイプ、ゲノグループそれぞれの分布が3つの独立した正規分布になる必要がある。ポリメラーゼ領域の塩基配列を用いた場合、この3つの正規分布が独立せず、互いに重なってしまい、アイソレートもしくはストレイン、ゲノタイプ、ゲノグループの区別を客観的に判断できない事が報告されている(9)。従って、客観的にアイソレートもしくはストレイン、ゲノタイプ、ゲノグループの区別には他の尺度に頼る必要がある。
ノロウイルスタイピングの今後
冒頭にも述べたように、ノロウイルスには、多くのリコンビナントが報告されている。リコンビナント株はノロウイルスに限らずサポウイルスでも報告されており(8)、ORF1/2 junction region を基点に遺伝子組み換えが頻繁に起きるのが、カリシウイルスファミリーに共通の特徴なのかもしれない。ORF1は、非構造蛋白質、ORF2, 3は構造蛋白質がコードされており、ORF1/2 junction regionを挟んでコードされる蛋白質の性質が全く異なっているのが興味深い。仮に、ノロウイルスの複製効率、病原性に関与する蛋白質がORF1にコードされているとすると、ORF1を用いたタイピングとORF2, 3を用いたタイピングがそれぞれ異なる目的を持って行われる可能性がある。我々は、既報の配列データを用いたそれぞれのゲノタイピングを行いながら、遺伝子組み換えを考慮に入れた新しいタイピングシステムを構築する必要に迫られているのではないだろうか。
1. Bull, R. A., E. T. Tu, C. J. McIver, W. D. Rawlinson, and P. A. White. 2006. Emergence of a New Norovirus Genotype II.4 Variant Associated with Global Outbreaks of Gastroenteritis. J Clin Microbiol 44:327-33.
2. Green, K. Y., G. Belliot, J. L. Taylor, J. Valdesuso, J. F. Lew, A. Z. Kapikian, and F. Y. Lin. 2002. A predominant role for Norwalk-like viruses as agents of epidemic gastroenteritis in Maryland nursing homes for the elderly. J Infect Dis 185:133-46.
3. Hansman, G. S., K. Natori, H. Shirato-Horikoshi, S. Ogawa, T. Oka, K. Katayama, T. Tanaka, T. Miyoshi, K. Sakae, S. Kobayashi, M. Shinohara, K. Uchida, N. Sakurai, K. Shinozaki, M. Okada, Y. Seto, K. Kamata, N. Nagata, K. Tanaka, T. Miyamura, and N. Takeda. 2006. Genetic and antigenic diversity among noroviruses. J Gen Virol 87:909-19.
4. Hansman, G. S., T. Oka, K. Katayama, and N. Takeda. 2007. Human sapoviruses: genetic diversity, recombination, and classification. Rev Med Virol 17:133-41.
5.Jiang, X., C. Espul, W. M. Zhong, H. Cuello, and D. O. Matson. 1999. Characterization of a novel human calicivirus that may be a naturally occurring recombinant. Arch Virol 144:2377-87.
6. Kageyama, T., S. Kojima, M. Shinohara, K. Uchida, S. Fukushi, F. B. Hoshino, N. Takeda, and K. Katayama. 2003. Broadly reactive and highly sensitive assay for Norwalk-like viruses based on real-time quantitative reverse transcription-PCR. J Clin Microbiol 41:1548-57.
7. Kageyama, T., M. Shinohara, K. Uchida, S. Fukushi, F. B. Hoshino, S. Kojima, R. Takai, T. Oka, N. Takeda, and K. Katayama. 2004. Coexistence of multiple genotypes, including newly identified genotypes, in outbreaks of gastroenteritis due to Norovirus in Japan. J Clin Microbiol 42:2988-95.
8. Katayama, K., T. Miyoshi, K. Uchino, T. Oka, T. Tanaka, N. Takeda, and G. S. Hansman. 2004. Novel recombinant sapovirus. Emerg Infect Dis 10:1874-6.
9. Katayama, K., H. Shirato-Horikoshi, S. Kojima, T. Kageyama, T. Oka, F. Hoshino, S. Fukushi, M. Shinohara, K. Uchida, Y. Suzuki, T. Gojobori, and N. Takeda. 2002. Phylogenetic Analysis of the Complete Genome of 18 Norwalk-like Viruses. Virology 299:225.
10.Ozawa, K., T. Oka, N. Takeda, and G. S. Hansman. 2007. Norovirus infections in symptomatic and asymptomatic food-handlers in Japan. J Clin Microbiol.
11.Siebenga, J. J., H. Vennema, E. Duizer, and M. P. Koopmans. 2007. Gastroenteritis caused by norovirus GGII.4, The Netherlands, 1994-2005. Emerg Infect Dis 13:144-6.
12.Siebenga, J. J., H. Vennema, B. Renckens, E. de Bruin, B. van der Veer, R. J. Siezen, and M. Koopmans. 2007. Epochal Evolution of GGII.4 Norovirus Capsid Proteins from 1995 to 2006. J Virol.
13.Vinje, J., H. Vennema, L. Maunula, C. H. von Bonsdorff, M. Hoehne, E. Schreier, A. Richards, J. Green, D. Brown, S. S. Beard, S. S. Monroe, E. de Bruin, L. Svensson, and M. P. Koopmans. 2003. International collaborative study to compare reverse transcriptase PCR assays for detection and genotyping of noroviruses. J Clin Microbiol 41:1423-33.
14.Zheng, D. P., T. Ando, R. L. Fankhauser, R. S. Beard, R. I. Glass, and S. S. Monroe. 2005. Norovirus classification and proposed strain nomenclature. Virology.
国立感染症研究所ウイルス第二部 片山和彦
 IASRのホームページに戻る
IASRのホームページに戻る Return to the IASR HomePage(English)
Return to the IASR HomePage(English)


{kind=link}